GPU Skin这门技术在端游时代属于标配,特别是MMO游戏,但是手游时代就要case by case了,因为手机的GPU资源还是很珍贵的(后处理之类的)。作为技术人员,这门手艺不能丢,所以还是说一下GPU Skin。下面需要先转载三篇文章,介绍了两种GPU Skin的原理以及Unity中GPU Skin的使用方法。,一篇来自陈嘉栋(慕容小匹夫),链接为:http://www.cnblogs.com/murongxiaopifu/p/7250772.html。一篇来自UWA,链接为:https://blog.uwa4d.com/archives/Sparkle_GPUSkinning.html。还有一篇来自Gad-腾讯游戏开发者平台,链接为:http://www.sohu.com/a/127714410_466876。
利用GPU实现大规模动画角色的渲染(转载自陈嘉栋(慕容小匹夫),链接为:http://www.cnblogs.com/murongxiaopifu/p/7250772.html)
前言
我想很多开发游戏的小伙伴都希望自己的场景内能渲染越多物体越好,甚至是能同时渲染成千上万个有自己动作的游戏角色就更好了。
但不幸的是,渲染和管理大量的游戏对象是以牺牲CPU和GPU性能为代价的,因为有太多Draw Call的问题,如果游戏对象有动画的话还会涉及到cpu的蒙皮开销,最后我们必须找到其他的解决方案。那么本文就来聊聊利用GPU实现角色的动画效果,减少CPU端的蒙皮开销;同时将渲染10,000个带动画的模型的Draw Call从10,000+减少到22个。(模型来自:RTS Mini Legion Footman Handpainted)

Animator和SkinnedMeshRender的问题
正常情况下,大家都会使用Animator来管理角色的动画,而角色也必须使用SkinnedMeshRender来进行渲染。

例如在我的测试场景中,默认情况下渲染10,000个带动作的士兵模型,可以看到此时的各个性能指标十分糟糕:CPU 320+ms,DrawCall:8700+。

因此,可以发现如果要渲染的动画角色数量很大时主要会有以下两个巨大的开销:
- CPU在处理动画时的开销。
- 每个角色一个Draw Call造成的开销。
CPU的这两大开销限制了我们使用传统方式渲染大规模角色的可能性。因此一些替代方案——例如广告牌技术(在纸片人)——被应用在这种情况下。但是实事求是的说,在这种情境下广告牌技术的实现效果并不好。
那么有没有可能让我们使用很少的开销就渲染出大规模的动画角色呢?
其实我们只需要回过头看看造成开销很大的原因,解决方案已经藏在问题之中了。
首先,主要瓶颈之一是角色动画的处理都集中在CPU端。因此一个简单的想法就是我们能否将这部分的开销转移到GPU上呢?因为GPU的运算能力可是它的强项。
其次,瓶颈之二是CPU和GPU之间的Draw Call问题,如果利用批处理(包括Static Batching和Dynamic Batching)或是从Unity5.4之后引入的GPU Instancing就可以解决这个问题。但是,不幸的是这两种技术都不支持动画角色的SkinnedMeshRender。
那么解决方案就呼之欲出了,那就是将动画相关的内容从CPU转移到GPU,同时由于CPU不需要再处理动画的逻辑了,因此CPU不仅省去了这部分的开销而且SkinnedMeshRender也可以替换成一般的Mesh Render,我们就可以很开心的使用GPU Instancing来减少Draw Call了。
Vertex Shader和AnimMap
写过shader的小伙伴可能很清楚,我们可以很方便的在vs中改变网格的顶点坐标。因此,一些简单的动画效果往往可以在vs中实现。例如飘扬的旗帜或者是波浪等等。

(来源于bing搜索)
那么我们能否利用vs设置顶点坐标的方式来展现我们的角色动画呢?

答案当然是可行。只不过和飘扬的旗帜那种简单的效果不同,这次我们不仅仅利用几个简单的vs的属性来实现动画效果,而是将角色的动画信息烘焙成一张贴图供vs使用。
简单来说,我们按照固定的频率对角色动画取样并记录取样点时刻角色网格上各个顶点的位置信息,并利用贴图的纹素的颜色属性(Color(float r, float g, float b, float a))保存对应顶点的位置(Vector3(float x, float y, float z))。当然利用颜色属性保存顶点的位置信息时需要考虑到一个小问题,在下文我会再说。
这样该贴图就记录了整个动画时间内角色网格顶点在各个取样点时刻的位置,这个贴图我把它称为AnimMap。
一个AnimMap的结构就是下图这样的:
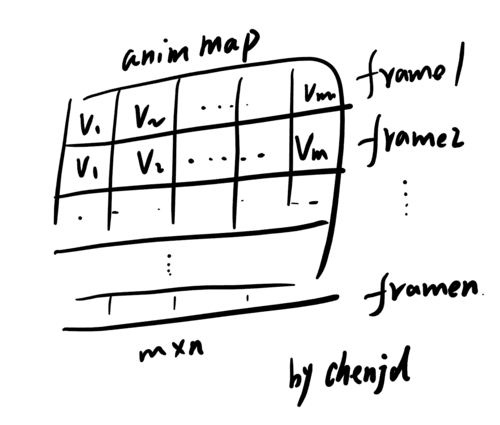
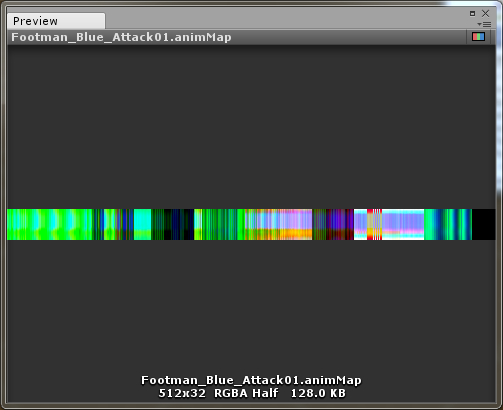
在实际工程中,AnimMap是这个样子的。水平方向记录网格各个顶点的位置,垂直方向是时间信息。

上图是将角色的Animator或Animation去掉,将SkinnedMeshRender更换为一般的Mesh Render,只使用AnimMap利用vs来随时间修改顶点坐标实现的动画效果。
到这里我们就完成了将动画效果的实现从CPU转移到GPU运算的目的,可以看到在CPU的开销统计中已经没有了动画相关的内容。但是在渲染的统计中,Draw Call并没有减少,此时渲染8个角色的场景内仍然有10个Draw Call的开销。因此下一步我们就来利用GPU Instancing技术减少Draw Call。(Patrick:飘扬的旗帜是无法使用批处理合并DC的,因为在VS中需要使用到模型在模型空间的坐标,而通过批处理合并DC之后,就只剩下世界空间的坐标了,而这篇文章介绍的这种GPU Skin也无法使用批处理的,因为VS中使用到了SV_VertexID。而且如果使用GPU Instancing的话,可以通过SV_InstanceID使得每个物件不同步的播放动画。还一个问题,就是有些GPU(DX9/11)在VS阶段不支持tex2D运算,因为在VS阶段Shader无法拿到lod信息,所以在这些GPU中的VS阶段中访问shader,需要用tex2Dlod函数)
效果不错的GPU Instancing
除了使用批处理,提高图形性能的另一个好办法是使用GPU Instancing(批处理可以合并不同的mesh,而GPU Instancing主要是针对同一个mesh来的)。
GPU Instancing的最大优势是可以减少内存使用和CPU开销。当使用GPU Instancing时,不需要打开批处理,GPU Instancing的目的是一个网格可以与一系列附加参数一起被推送到GPU。要利用GPU Instancing,则必须使用相同的材质,并传递额外的参数到着色器,如颜色,浮点数等。
不过GPU Instancing是不支持SkinnedMeshRender的,也就是正常情况下我们带动画的角色是无法使用GPU Instancing来减少Draw Call的,所以我们必须先完成上一小节的目标,将动画逻辑从CPU转移到GPU后就可以只使用Mesh Render而放弃SkinnedMeshRender了。
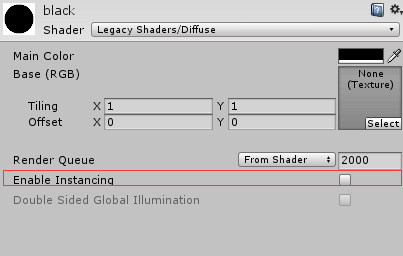
很多build-in的shader默认是有开启GPU Instancing的选项的,但是我们利用AnimMap实现角色动画效果的shader显然不是build-in,因此需要我们自己开启GPU Instancing的功能。
#pragma multi_compile_instancing//告诉Unity生成一个开启instancing功能的shader variant...
struct appdata
{
float2 uv : TEXCOORD0;
UNITY_VERTEX_INPUT_INSTANCE_ID//用来给该顶点定义一个instance ID
}
v2f vert(appdata v, uint vid : SV_VertexID, uint iid : SV_InstanceID)
{
UNITY_SETUP_INSTANCE_ID(v);//让shader的方法可以访问到该instance ID
...
}
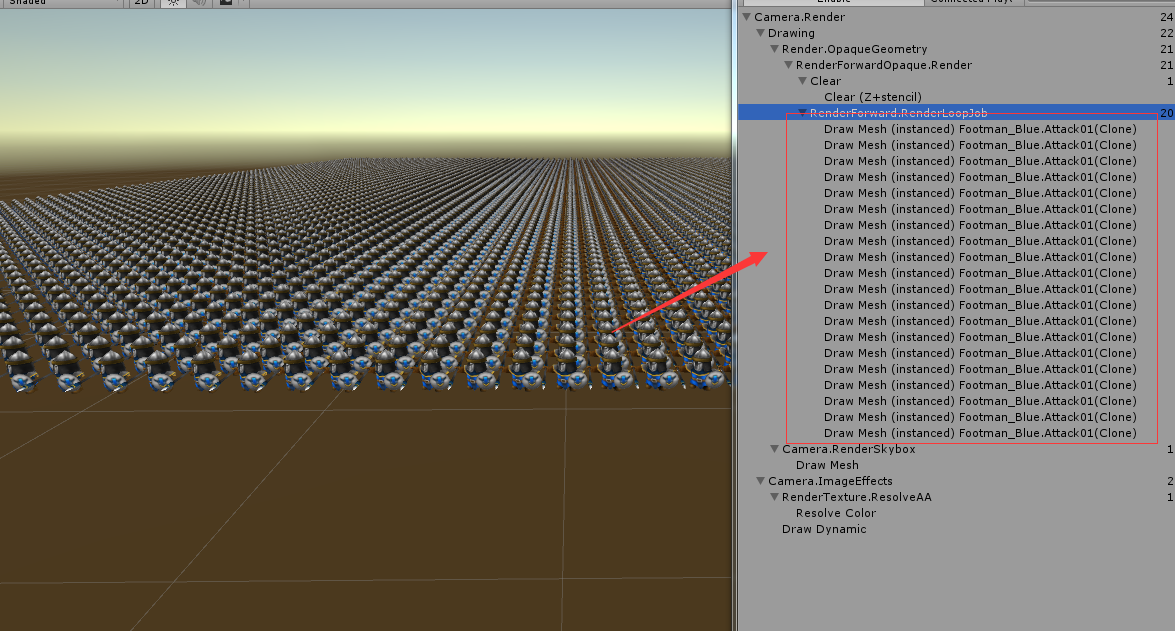
使用GPU Instancing之后,我们渲染10,000个士兵的Draw Call就从10,000左右降低到20上下了。
当然,关于GPU Instancing的更多内容各位可以在文末的参考链接中找到。
颜色精度和顶点坐标
还记得之前我说过在利用贴图的纹素的颜色属性保存对应顶点的位置时需要考虑到的一个小问题吗?
是的,那就是颜色的精度问题。
由于现在rgb分别代表了坐标的x、y、z,因此rgb的精度就要好好考虑了。例如rgba32,每个通道只有8位,也就是某一个方向上的位置只有256种可能性,这对位置来说是一个不好的限制。
那么有没有解决方案呢?
当然还是有的。既然这是一个和颜色的精度相关的问题,那么最简单的方案就是增加精度。例如在写本文的时我的Demo就是采用的这种方式,我使用了RGBAHalf这种纹理格式,而它的精度是每个通道16bit。当然,移动平台上渲染大量角色的需求往往对动画的精确程度的要求没有那么高,因此8bit的精度问题应该也不大。
完整的项目可以到这里到这里下载:Render-Crowd-Of-Animated-Characters
Patrick:上面这个方法非常酷炫,用空间换取时间,用纹理保存了所有顶点在关键帧的位置信息,这样优点是连GPU Skin都不需要了。。GPU中不需要计算顶点位置,直接从纹理中读取即可。缺点是纹理大小是个问题,粒子中用的是512个顶点(或者以内)的mesh,采样了32帧(或者以内),使用RGBAHalf的格式,占内存大小是512*32*64/(8 * 1024) = 128KB,对于顶点数量数千的角色mesh,一个动作就超过1M,一个角色少数也有一二十个动作,那么一个角色就一二十M,即使不是同时出现的动作,内存不会同时占用,那么包体大小也是个问题(不过针对顶点数量少的还是不错的,附上一个我从UE4.16源码中扒出来的3D Max脚本VertexAnimationTools,用于将动作生成AnimMap)。所以下面要介绍的另外一个方案,是属于比较规矩的GPU Skin,在VS中通过骨骼和模型在模型空间的坐标做GPU Skin。
GPU Skinning 加速骨骼动画(转载自UWA,链接为:https://blog.uwa4d.com/archives/Sparkle_GPUSkinning.html)
起因
我们知道,场景中有很多人物动画模型的时候,性能会产生大量开销。这些开销除了 Draw Call 外,很大一部分来自于骨骼动画。Unity 内置了 GPU Skinning 功能,但笔者测试下来并没有对整体性能有任何提升,反而增加了不少。有很多种方法来减小骨骼动画的开销(Patrick:减小骨骼动画的开销?不知道这个作者是不是想减小Unity AnimationClip的大小,由于每一帧中不是所有的骨骼都会动,那么将关键帧中不需要使用的骨骼信息删掉就可以减小这个大小。然后通过Unity提供的压缩格式对AnimationClip进行保存,至于使用哪个压缩格式,参考UWA文档Unity加载模块深度解析之动画资源),每一种方法都有其利弊,都不是万金油,这里介绍的方法同样如此。其实本质还是由我们自己来实现 GPU Skinning,只是和 Unity 内置的 GPU Skinning 有所区别。


使用了 ShadowGun中的角色模型

开启 Unity 内置的 GPU Skinning
从上图中可以看到,Unity 调用到了OpenGL ES 的 Transform Feedback 接口,这个接口至少要在 OpenGL ES 3.0 中才有。笔者理解的 Transform Feedback,就是将大批的数据传递给 Vertex Shader,将 GPU 计算过后的结果通过一个 Buffer Object 返回到 CPU 中,CPU 再从 Buffer Object 读取数据(或直接将 Buffer Object 传递给下一步),在随后步骤中使用。显然,在骨骼动画中,TransformFeedback 负责骨骼变换,Unity 将变换后的结果拿来再进行 GPU 蒙皮操作。(Patrick:在VS中计算好了之后还用TFBO传回给CPU干啥?只是为了再重新经过另外一个VS的时候,因为不需要使用模型空间坐标了,可以批处理合并DC?)
这次我们要动手实现的就是这个过程,但是不使用 Transform Feedback,因为要保证在 OpenGL ES 2.0 上也能良好运行,况且Unity引擎也没有提供这么底层的接口。
大致的步骤如下:
- 将骨骼动画数据序列化到自定义的数据结构中。这么做是因为这样能完全摆脱 Animation 的束缚(Patrick:怎么摆脱?),并且可以做到 Optimize GameObjects(Unity 中一个功能(Patrick:在哪里?),在不丢失绑点的情况下将骨骼的层级结构 GameObjects 完全去掉,减少开销);
- 在 CPU 中进行骨骼变换;
- 将骨骼变换的结果传递给 GPU,进行蒙皮。
很简单的三大步骤,对于传统的骨骼动画来说没有任何特殊情况,下面我会对其中的每一步展开说明,并将其中的细节描述清楚。
实现
提取骨骼动画数据
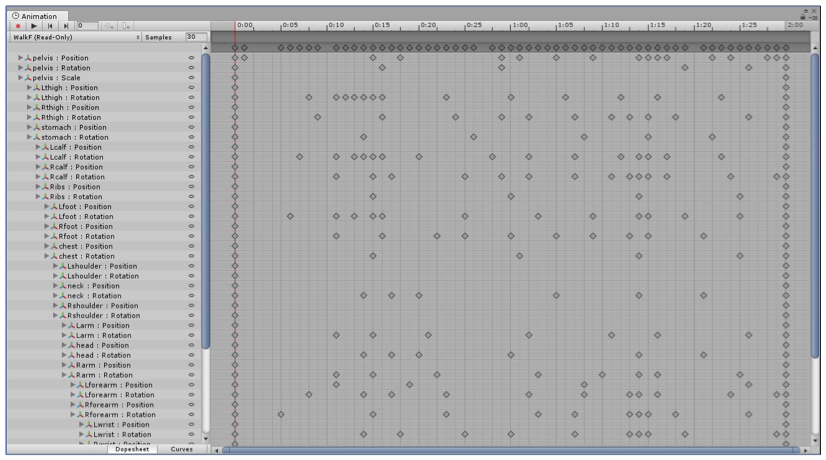
Unity 中的 Animation 数据
这个步骤的目的就是将这些数据提取出来,存储到自定义的数据结构中。代码大致如下:
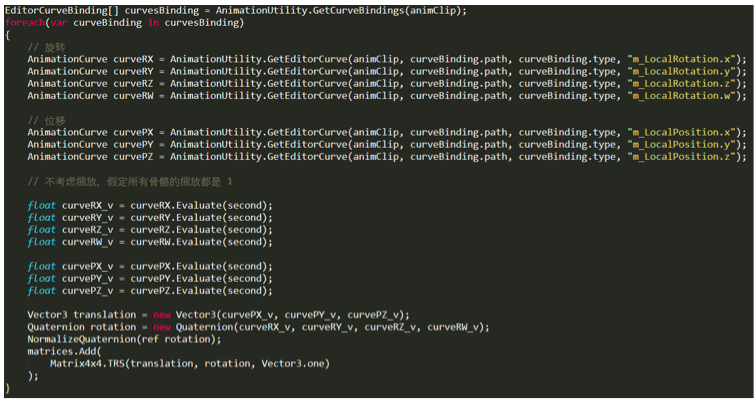
其中有两个注意点。第一,要清楚 AnimationCurve 中提取出来的旋转量是欧拉角还是四元数。这里我一开始就弄错了,想当然认为是欧拉角,所以随后计算得到的结果也就错了。第二,用来旋转的四元数,必须是单位四元数(模是1),否则你会得到 Unity 的一个报错信息。(Patrick:这一块比较复杂,需要实际操作一遍。。)
以上的代码中,我将每一帧的数据以 30fps 的频率直接采样了出来,其实也可以不采样出来,而是等需要的时候再从 AnimationCurve 中采样,这样会更平滑但是运行时的计算量也更多了。(Patrick:还没想到应该如何做。。)
骨骼变换
骨骼变换是所有代码的核心部分了,看似挺复杂,其实想清楚后代码量是最少的:
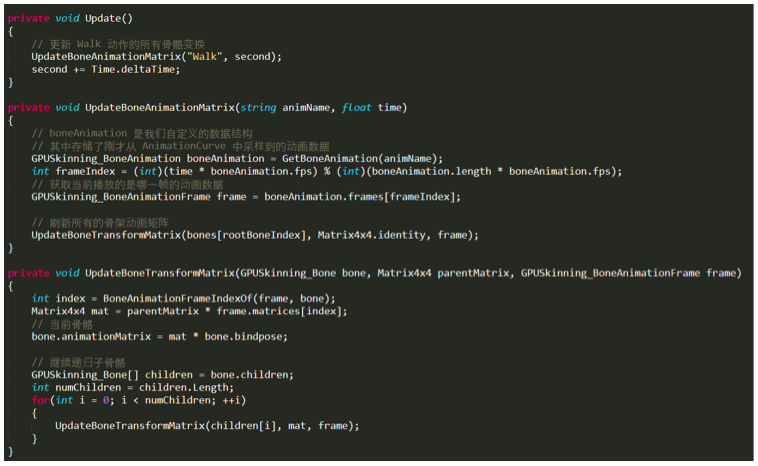
简单来说骨骼变换就是一个矩阵乘法,比如 bone0(简写为b0) 是 bone1(简写为b1)的父骨骼:

注意这里是矩阵左乘(从右往左读),trs 是 Matrix4x4.TRS,也就是从 AnmationCurve 采样到的数据。
Bindpose 的作用是将模型空间中的顶点坐标变换到骨骼空间中(是骨骼矩阵的逆矩阵),然后应用当前骨骼的变换,沿着层级关系一层层地变换下去。
蒙皮
蒙皮CPU部分的代码如下:
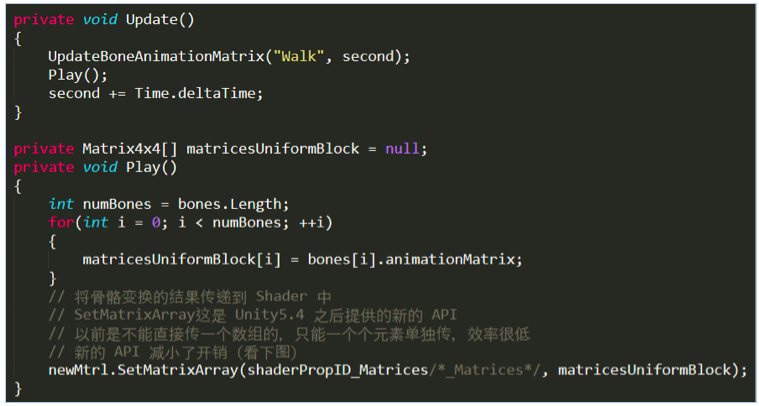


由于骨骼数量固定为 24,所以图中的 96 = 24 x 4(Patrick:Uniform有数量限制,所以骨骼也就有数量限制。)
GL_MAX_COMBINED_FRAGMENT_UNIFORM_COMPONENTS = GL_MAX_FRAGMENT_UNIFORM_COMPONENTS + GL_MAX_UNIFORM_BLOCK_SIZE * GL_MAX_FRAGMENT_UNIFORM_BLOCKS / 4 GL_MAX_COMBINED_UNIFORM_BLOCKS = 24 GL_MAX_COMBINED_VERTEX_UNIFORM_COMPONENTS = GL_MAX_VERTEX_UNIFORM_COMPONENTS + GL_MAX_UNIFORM_BLOCK_SIZE * GL_MAX_VERTEX_UNIFORM_BLOCKS / 4 GL_MAX_FRAGMENT_UNIFORM_BLOCKS = 12 GL_MAX_FRAGMENT_UNIFORM_COMPONENTS = 896 GL_MAX_FRAGMENT_UNIFORM_VECTORS = 224(ES3.0)/16(ES2.0) GL_MAX_UNIFORM_BLOCK_SIZE = 16384 GL_MAX_UNIFORM_BUFFER_BINDINGS = 24 GL_MAX_VERTEX_UNIFORM_BLOCKS = 12 GL_MAX_VERTEX_UNIFORM_COMPONENTS = 1024 GL_MAX_VERTEX_UNIFORM_VECTORS = 256(ES3.0)/128(ES2.0)
使用 SetMatrixArray 其实有点浪费了,因为对于一个 4x4 的矩阵(四个 float4 )来说,最后一维永远是 (0, 0, 0, 1),所以可以使用 3x4 的矩阵(三个float4)代替,这样就减少了数据传递的压力。
现在所有的骨骼变换矩阵已经传递到 Shader 中了,就可以使用这些数据来进行蒙皮(变换顶点坐标)。
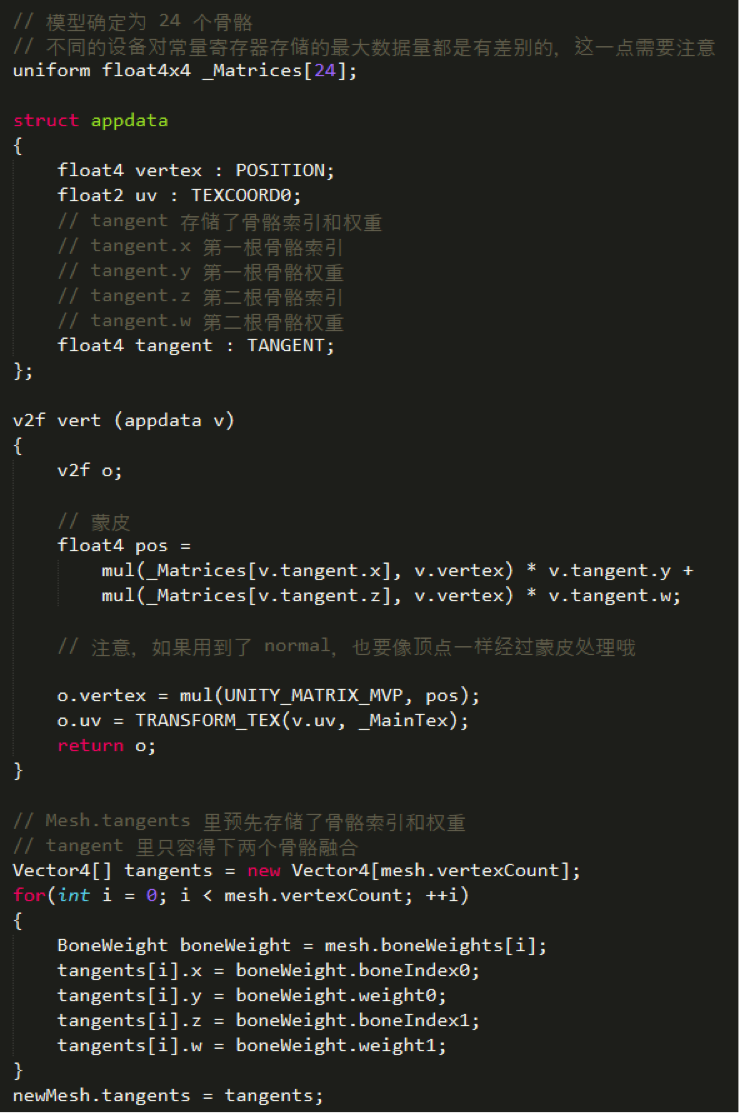
改进
此时所有角色的动作都是同步的。接下来进行改进,不再使用 uniform array 的方式来传递数据,而是将骨骼动画数据存储到纹理中,并加以一定的差异化,避免所有角色的动作完全同步的问题。(Patrick:这种方法有点类似上面两个办法的结合,又规避了第二种办法骨骼有限制的问题,又规避了第一种办法纹理过大的问题,第二种办法纹理大小,24个骨骼32帧大小为:24*4*32*32/8/1024=12KB。但是在下面的shader中只看到了Time一个变量,所以应该每个物件没什么太大差异性的,差异性主要还是靠GPU Instance,然而由于依然是使用Skin mesh,所以这个方法没法用GPU Instance。)在运行的最开始,将所有帧的动画数据存储到纹理中,代码如下:
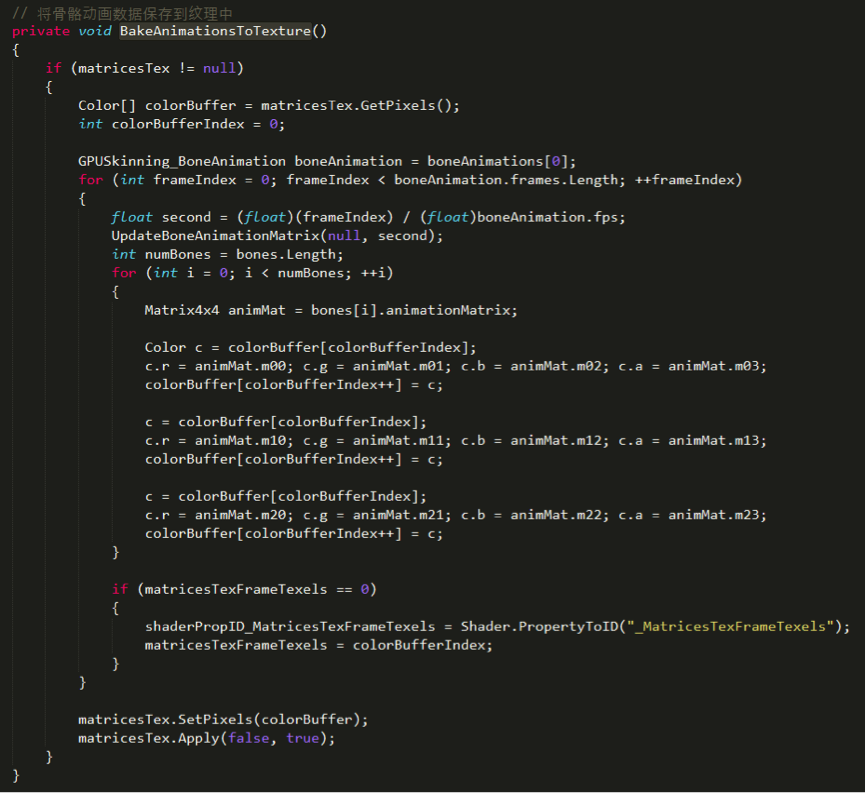
Shader中的蒙皮代码相应变为:
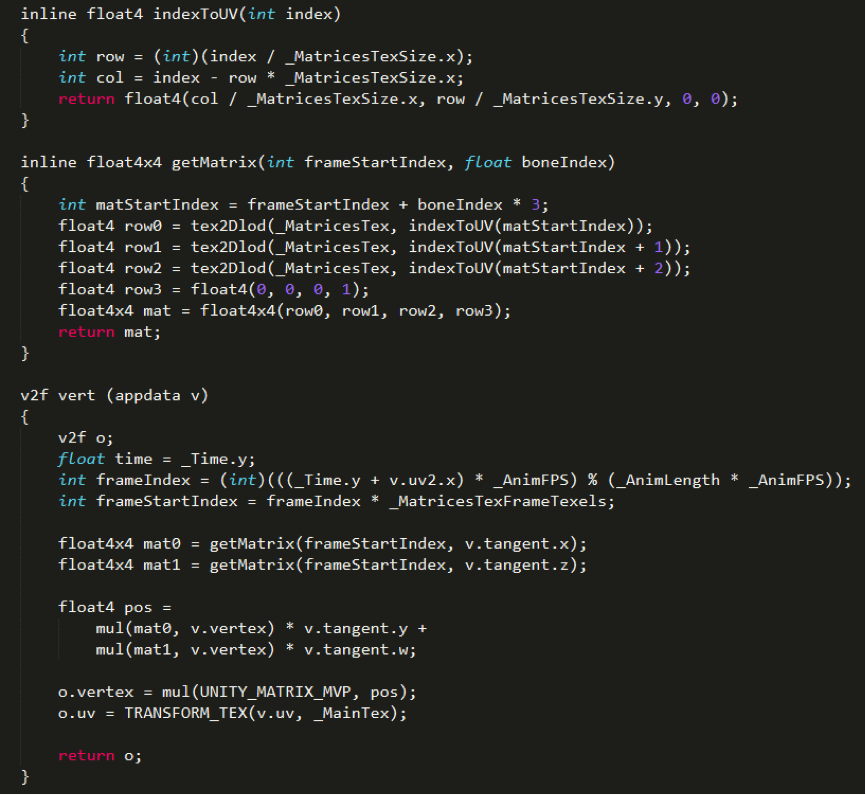
以上就是笔者实现 GPU Skinning 的细节。但没有一种方法是完美的,作为能够减少骨骼动画开销的备选方案之一,在恰当的情况下使用会大大地提高性能。
测试
为了进一步验证该方案在移动设备上的可行性,UWA在真机上进行如下了实验。
我们在一个空场景中放置一定数目的模型播放动画,对 Mecanim 和 GPU Skinning 的运行效率进行对比。模型取自 ShadowGun,具有2600面片,24根骨骼。使用 Mecanim 时,模型使用 Generic 模式,并且使用 Optimize GameObject。在红米Note2运行1000帧的数据如下:
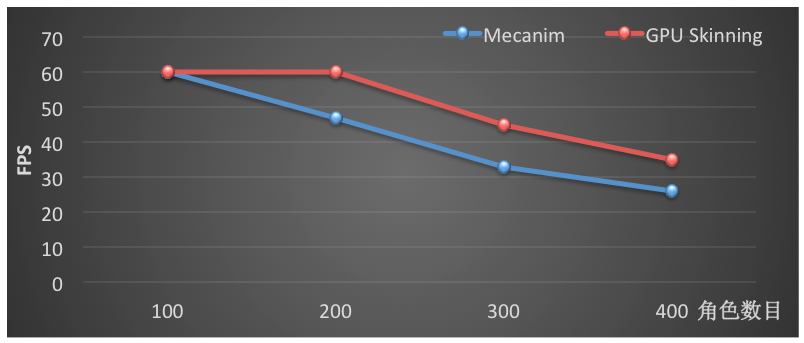
FPS 变化
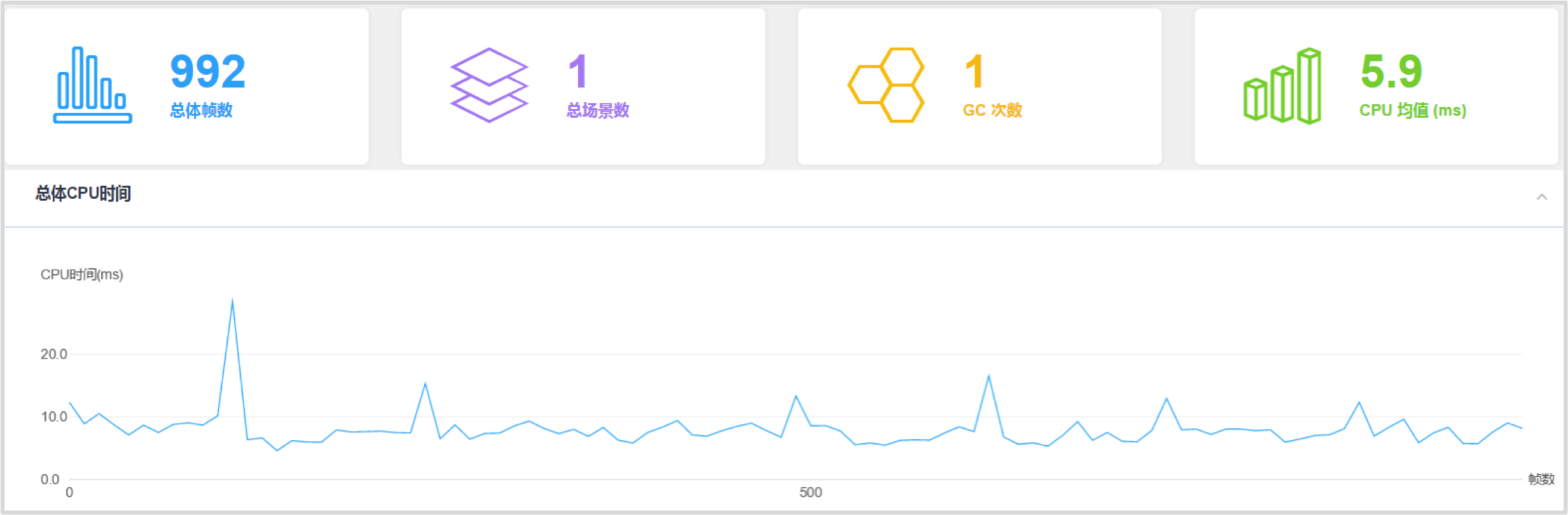
测试场景 CPU 耗时数据
上图是GPU Skinning方案在场景中存在300个角色时的主线程 CPU 耗时数据。不同角色数目的平均每帧 CPU 耗时(主线程)如下:
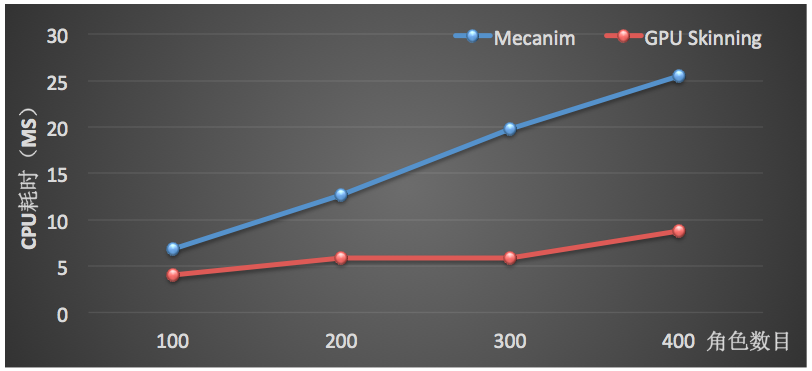
从数据可以看出,不论从整体的 FPS还是主线程平均每帧的 CPU 耗时,GPU Skinning都表现出了更好的性能,从而可以让宝贵的 CPU 耗时用于更多的游戏逻辑。
优点和局限性
该方法将CPU中的蒙皮工作转移到 GPU 中进行,真机上的测试数据验证了该方法能够较大地提升多角色场景的运行效率。该方法具备以下优点:
- 极大地降低 MeshSkinning.Render 的CPU耗时,同时还可以去除对 Animator 组件的依赖(Patrick:只需要一个animation组件和一个skin mesh组件即可。),从而完全避免 MeshSkinning.Update 和 Animator.Update 的 CPU 占用;
- 通过纹理保存动画数据,只需要少量内存开销即可带来巨大运行效率提升;
- 适用于大规模群体动画模拟,如 MMO、RTS 等游戏类型。
当然,该方法在当前也存在如下局限性:
- 增加 GPU 运算负担;
- 当前的 Shader 实现中使用了 tex2Dlod,该 API 在某些低端机型上可能存在适配问题;
- 目前还无法直接处理动画事件、动画融合等操作,需要研发团队进行进一步开发。
Patrick:转载了两篇文章了,我就把我自己的GPU Skin也放出来吧,用的方法和第二种方法的类似(不用纹理版),每个顶点跟三根骨骼关联,GPU Skin主要就是VS部分,那就把skinmesh.vs贴出来。下面转载的是腾讯对Unity内置GPU Skin的分析。
Unity引擎源码札记:GPUSkinning(转载自Gad-腾讯游戏开发者平台,链接为:http://www.sohu.com/a/127714410_466876)
Skinning设置
Unity支持GPU Skining,构建时开启PlayerSetting.gpuSkinning 将允许符合条件平台使用GPU Skinning (官方文档:DX11, OpenGL ES 3.0 and Xbox 360 can do mesh skinning on the GPU)。
BuildSetting(IOS/Android)
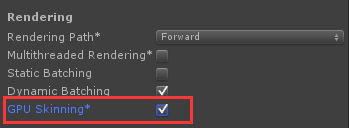
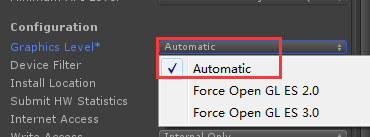
Android下需要额外设置(如果选择“Force Open GL ES 2.0”,在支持ES 3.0的设备上依然不会生效GPU Skinning,原因见下文源码分析):
适用设备(IOS/Android)
对于手机平台,IOS/Android,Opengl ES支持版本及设备如下:
OpenGL ES 2.0 Supported by:
- The Android platform since Android 2.0 through NDK and Android 2.2 through Java
- Apple iOS 5 or later in iPad, iPad Mini, iPhone 3GS or later, and iPod Touch 3rd generation or later
OpenGL ES 3.0 Supported by:
- Android since version 4.3, on devices with appropriate hardware and drivers, including:
Nexus 7 (2013)、 Nexus 4、 Nexus 5、 Nexus 10、 HTC Butterfly S、 HTC One/One Max、 LG G2、 LG G Pad 8.3、 Samsung Galaxy S4 (Snapdragon version)、 Samsung Galaxy S5、 Samsung Galaxy Note 3、 Samsung Galaxy Note 10.1 (2014 Edition)、 Sony Xperia M、 Sony Xperia Z/ZL、 Sony Xperia Z1、 Sony Xperia Z Ultra、 Sony Xperia Tablet Z - iOS since version 7, on devices including:
iPhone 5S、 iPad Air、 iPad mini with Retina display - Supported by some recent versions of these GPUs:
Adreno 300 and 400 series (Android, BlackBerry 10, Windows Phone 8, Windows RT)、 Mali T600 series onwards (Android, Linux, Windows 7)、 PowerVR Series6 (iOS, Linux)、 Vivante (Android, OS X 10.8.3, Windows 7)、 Nvidia (Android, Linux, Windows 7)、 Intel (Linux)
引擎源码分析
SkinnedMeshRenderer::AwakeFromLoad会创建当前平台的GPUSkinningInfo
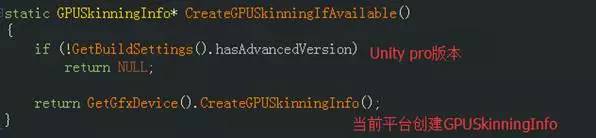
GLES 2.0将返回NULL,因此,若在BuildSetting时Graphic level选择“Froce Open GL 2.0”,GPUSkinningInfo为空,即使在支持 GLES 3.0的设备上,也不进行GPUSkinning.
SkinnedMeshRenderer::SkinMesh根据条件进行CPU 或 GPU Skinning计算,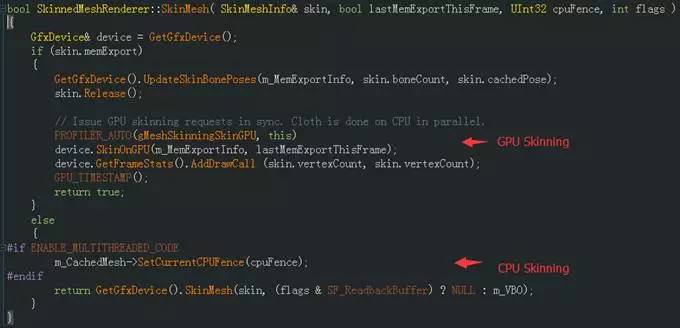
而skin.memExport条件取决于:
- PlayerSetting.gpuSkinning是否开启
- 当前初始创建的GPUSkinningInfo是否为NULL( 即m_MemExportInfo)
- 是否Cloth及是否具有skin信息、骨骼权重等
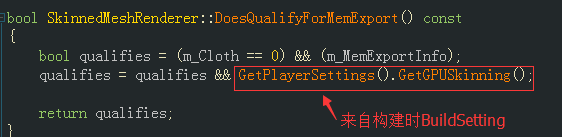
源码小结
从源码上看,如前文1)中的构建设置选项,构建时打开PlayerSetting.gpuSkinning (Andorid平台Graphic level: Automatic )在GLES 2.0设备上应会自动选择CPU Skinning,在GLES 3.0设备会使用GPU Skinning,实际情况需要进行目标机型的兼容性测试。
性能测试分析
使用不同数目的角色skinned mesh 测试CPU 负载情况:
测试数据(单机,不限帧,忽略流量,测试60s)
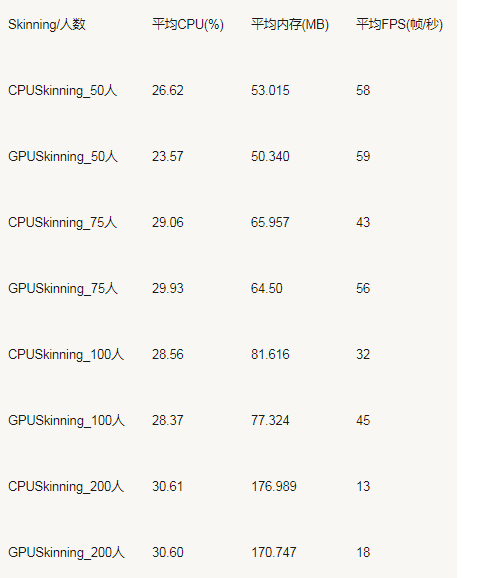
- 随人数增加,两者CPU负载趋一致,GPU Skinning比CPU Skinning内存稍低;
- 随人数增加,GPU Skinning比CPU Skinning FPS高30%左右;
- 75人以下,GPU Skinning 比 CPU Skinning的CPU负载稍低,内存较低,FPS相近(此时非GPU瓶颈);
小结
是否使用GPUSkinning策略,也取决于CPU或GPU的负载情况。如果当前的CPU负载瓶颈,GPU较轻,可使用GPUSkinning;反之,则建议使用默认的CPUSkinning。
值得注意的是,在项目中开启GPUSkinning后,部分机型会出现蒙皮错误,存在兼容性问题,但是使用CPUSkinning正常。因此,慎用Unity 4.6中的GPUSkinning(Unity 5没做测试未知),需要进行更多的兼容性测试和验证。(Patrick:总之Unity自带的GPU Skin貌似还是有蛮多坑的,所以还是自己写GPU Skin吧。)
虽然并非全部原创,但还是希望转载请注明出处:电子设备中的画家|王烁 于 2017 年 8 月 10 日发表,原文链接(http://geekfaner.com/unity/blog4_GPUSkin.html)