本节内容,来自Metal 2 on A11 - Tile Shading
关联阅读:
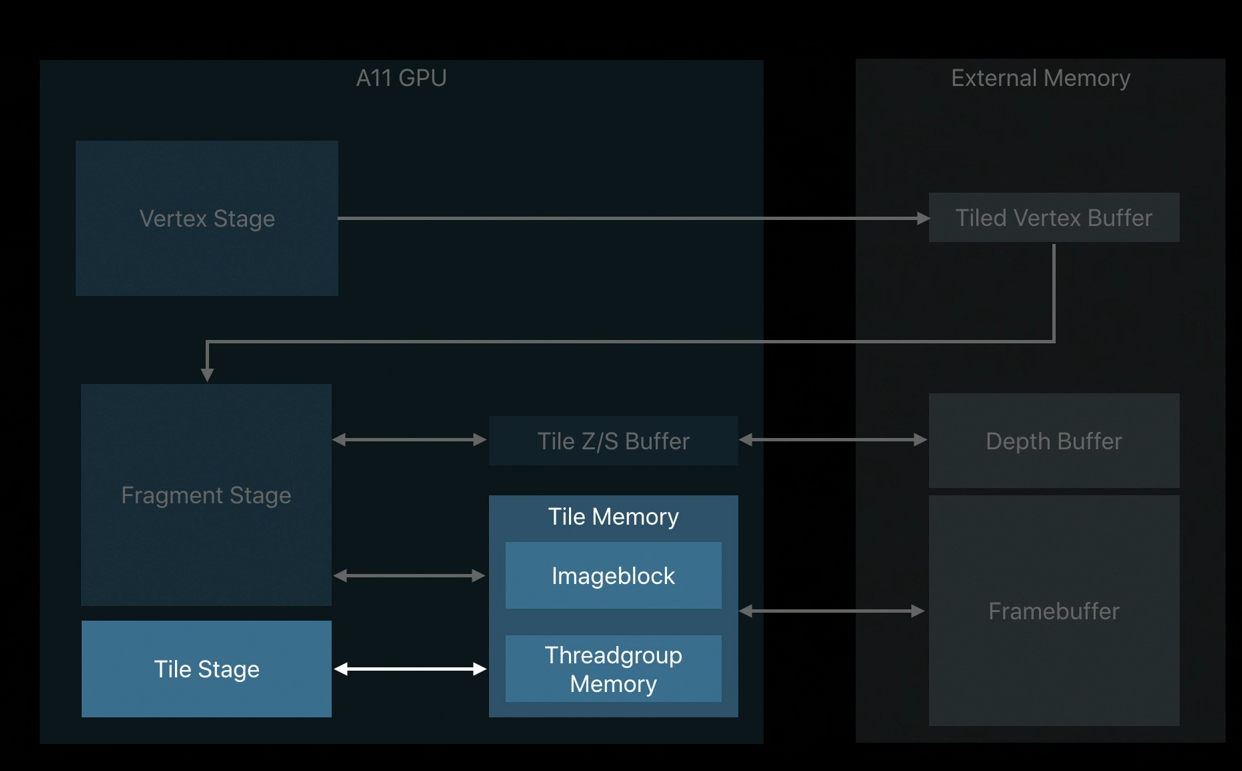
In this presentation we will focus on tile shading, the new programmable stage in Apple's A11 GPU that provides compute capabilities inline within render passes.
Tile shading enables a whole new level of performance and efficiency in Metal 2.
Rendering and compute operations can now share data through the higher bandwidth and lower power tile memory.
Tile shading is deeply integrated with imageblocks.
You'll be able to analyze imageblock contents, summarize that content, store imageblocks mid-scene, or even change imageblock layouts.
Tile shading is also tightly integrated with threadgroup memory and can be used to cache tile constant data for the later tile or fragment stages.
Let's start by motivating the need for tile shading.
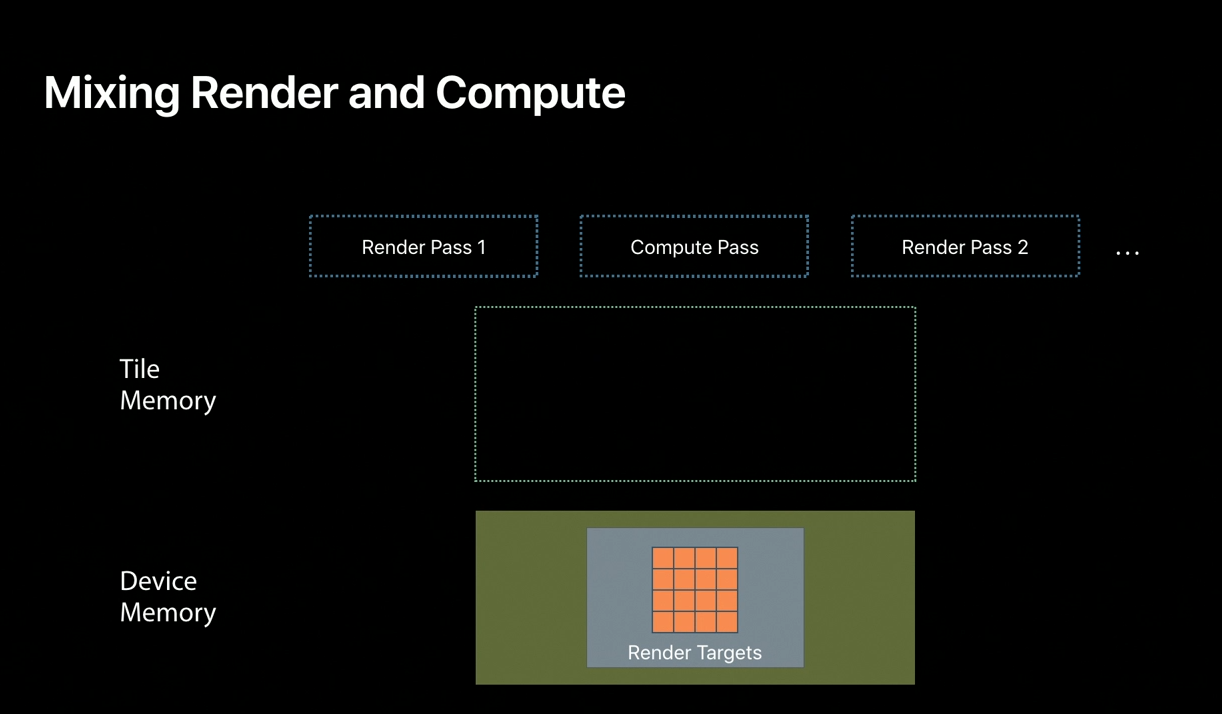
Performing compute between render passes has become more common in recent years.
For example, tiled deferred and forward rendering algorithms intersect lights against screen-aligned tiles in order to reduce shading cost.
The idea behind these algorithms is that not all lights affect all pixels, but culling per pixel may be too expensive, so we amortize the cost over tile regions.
Previously in Metal for A Series GPUs, performing compute mid-render required storing render target data that was cached in tile memory back out to device memory, so that a compute pass could then consume it.
Compute would then have to also store its results back to device memory before rendering would resume.
This repeated data movement between local and external memories is bandwidth intensive.
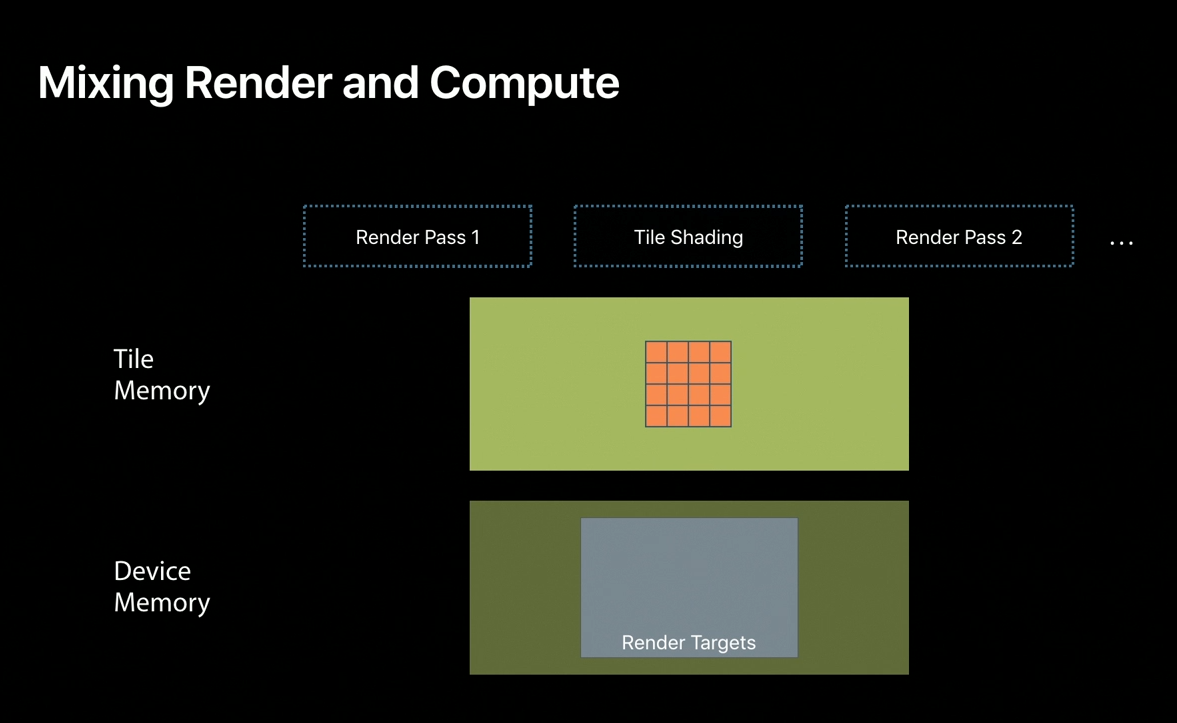
With Metal 2 and the A11 GPU, such algorithms can now operate exclusively within the exposed tile memory using tile shading, which takes the place of the compute pass.
Render target contents are now cached in tile memory once.
Tile shading then operates directly on the imageblock and can even its results to threadgroup memory, which is also backed by tile memory for later use by rendering.
Now that we've seen how tile shaders allow you to operate within tile memory more often, let's take a closer look at how tile shading interacts with draws.
Launching threads within a compute pass is called a dispatch, and Metal adopts the same name for tile shading operations within a render pass.
Tile dispatches may be freely interleaved with draws and are executed in API submission order.
Metal guarantees that the results of draws issued before the dispatch are visible when that dispatch is executed.
Likewise, Metal guarantees that the results of each dispatch are visible when the next draw or dispatch is executed.
This synchronization guarantee allows race-free access to tile memory.
No such guarantee is made between draws though.

Another important concept in tile shading is how threads are organized into threadgroups and grids.
With traditional compute dispatches, threadgroups are organized into tightly packed grids.
Within a render pass, however, the tile grid is constant across the entire pass, but the threadgroup size can differ for each dispatch.

If we zoom in on a tile, we see that this allows you to map each thread to a unique pixel or map each thread to multiple pixels.


The mapping of threads to resources has no special meaning to Metal though.
You can launch threads that have no mapping to pixels whatsoever, as would be the case for the light culling example we previously discussed.
In that example, your threadgroup size might match the number of lights that need intersection testing.
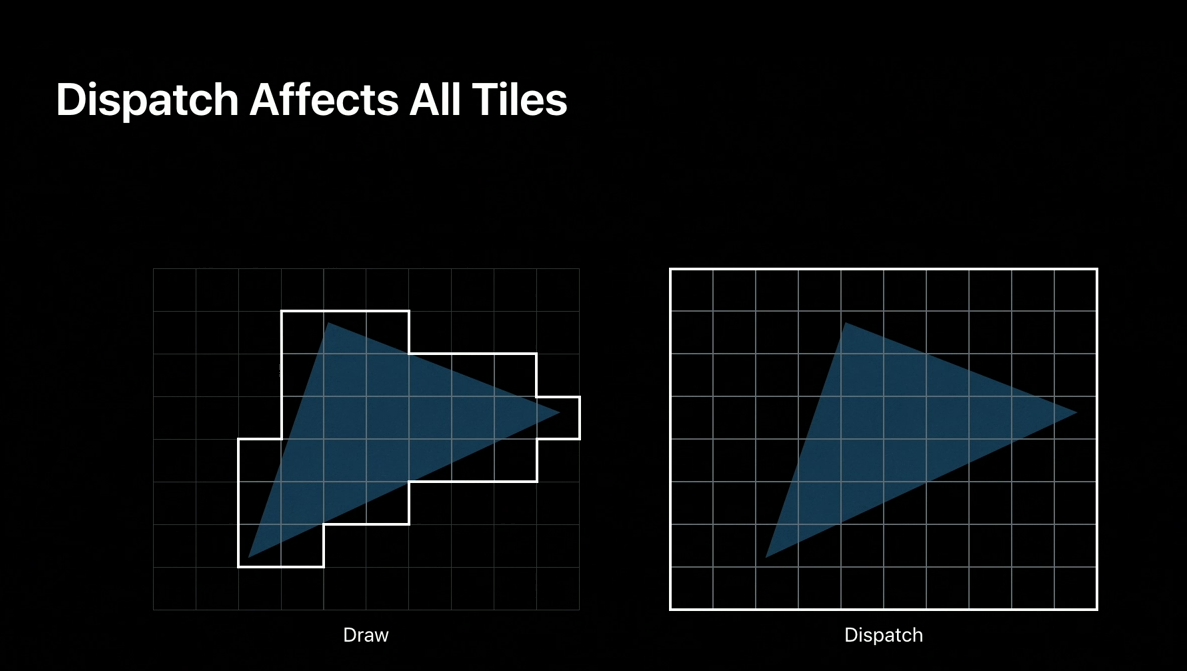
Tile shading threadgroups are launched for each tile regardless of any geometry present.
For example, a triangle affecting a subset of tiles, need only be processed by those tiles.
A subsequent tile dispatch, however, will be processed by every tile of the screen.
Doing so is important because that dispatch may be initializing tile memory for later geometry that can land in those tiles.
Viewport and scissor states do not restrict tile shading either.
In general, tile shading is unaffected by traditional render states.
OK, so now let's turn to the API changes that support tile shading.
A render pass can be configured with one of three tile sizes, which will determine your imageblock dimensions.
You most often want to choose the largest tile size that fits your imageblock -- which is 32 KB on A11 GPUs -- to minimize any overhead of the GPU's primitive processing stage.
Some algorithms may, however, benefit from choosing a smaller tile size when fragment or tile processing is particularly complex, to increase the amount of tile parallelism in the shader cores.
As we've already seen, threadgroup memory is also sourced from tile memory so it's size may also constrain your choice of tile size.

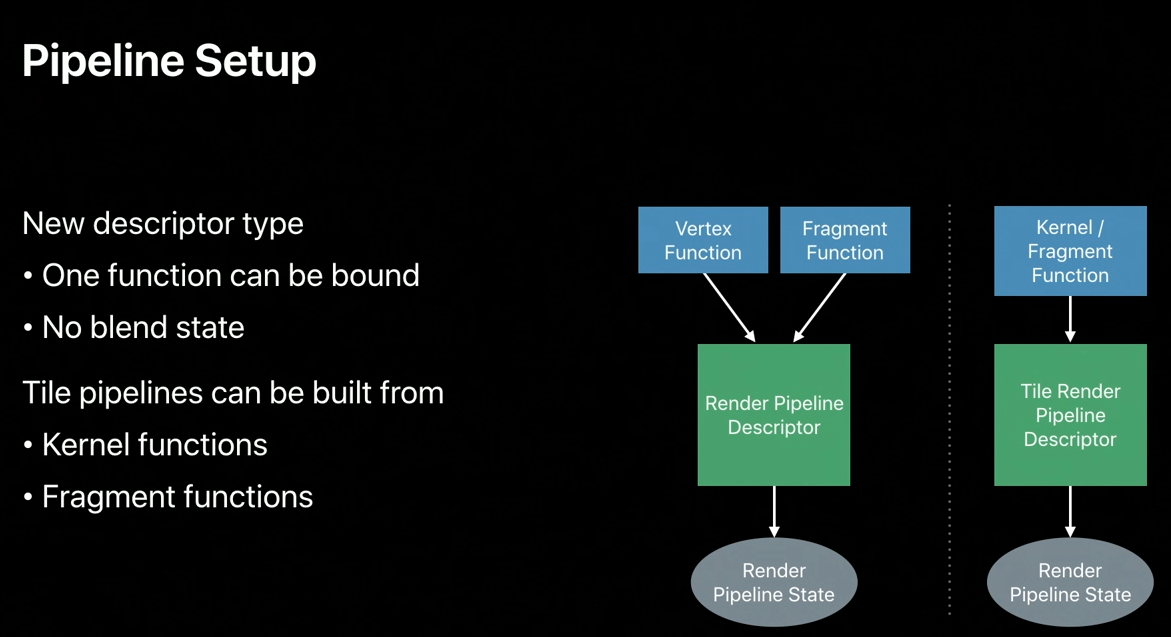
Creating a tile shading pipeline is similar to creating a traditional pipeline.
You attach functions to a pipeline descriptor to create a pipeline state.
For tile shading, Metal introduces a new pipeline descriptor type.
It's similar to the existing render pipeline descriptor, but removes render state properties such as blending.
It's also similar to the existing compute pipeline descriptor because only one function can be bound.
That function, however, can either be a compute kernel or a fragment function.
Compute kernels provide access to all the tile shading and imageblock features we've discussed so far.
Fragment-based tile shading is more limited but plays a specific and important role that I'll talk about later on.
First, I'd like to touch on imageblock capabilities in tile pipelines.
Since tile shading executes compute dispatches inline with rendering, it has access to both implicit and explicit imageblocks, just like fragment functions.
Unlike fragment functions, however, kernel-based tile shaders can access the entire imageblock.

Let's take a look at the syntax.
We disambiguate between the implicit and explicit forms of the templated imageblock type using a second template argument.
We must disambiguate because each has different access semantics.
The implicit form has value semantics, meaning that we copy pixels into and out of the imageblock.
The explicit form has the reference semantics discussed in the previous presentation.

We've already seen how imageblocks within a render pass persist for the lifetime of the tile and how we leverage this to communicate across draws and dispatches.
In our opening example I also mentioned that the same is true for threadgroup memory.
Persistent threadgroup memory is unique to tile shading and is well-suited for storing data that's constant across the tile, such as culled light lists.

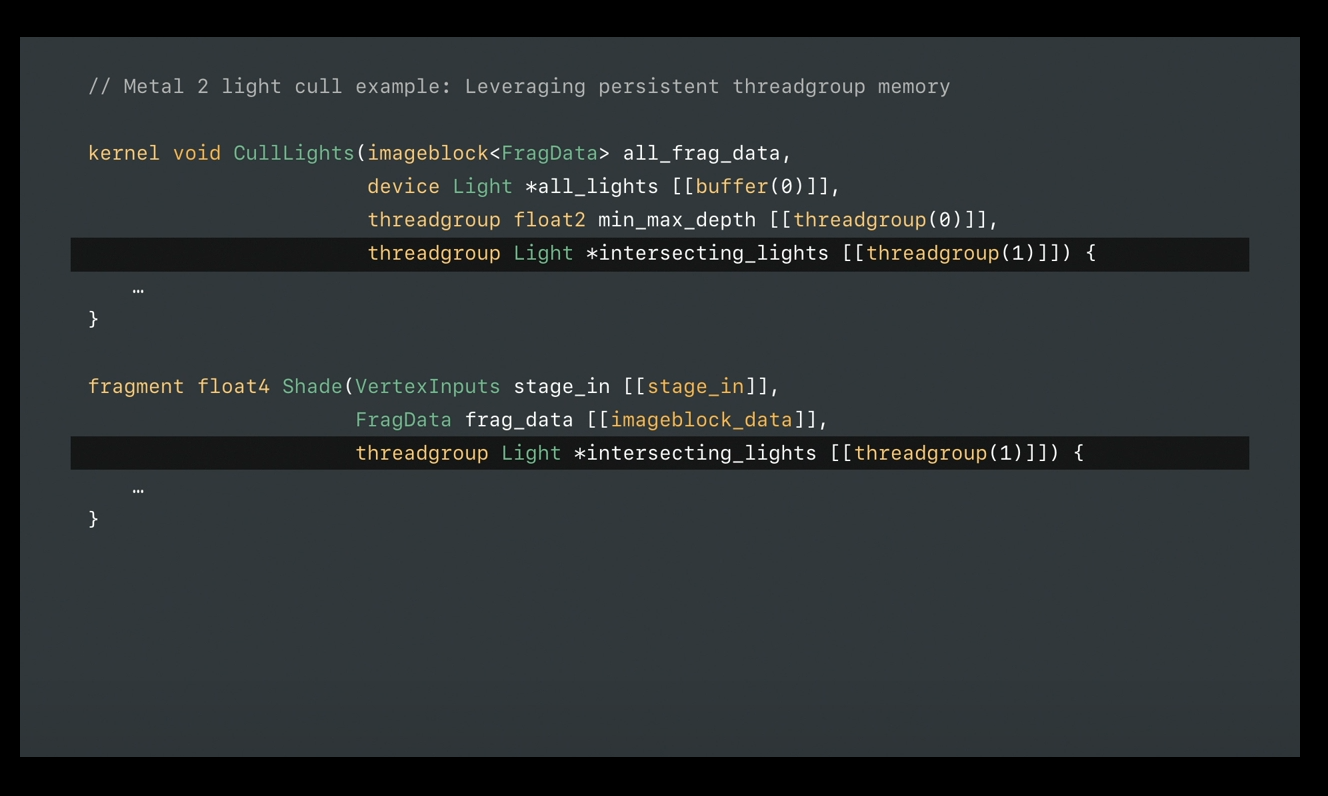
Let's take a look at how we leverage this in the shading language.
In this example, our kernel-based tile function is provided the full light list for culling against its tile bounds.
It's also given minimum and maximum depth of the tile from an earlier tile dispatch.
It then places the culled result in threadgroup memory so that later fragment shaders have access to it.
Both tile dispatch and fragment draws must agree on the threadgroup bind point.
Let's finally consider the role fragment-based tile pipelines play.
Tile shading encourages you to leverage tile memory by merging what would previously have been multiple passes.
Tile memory is a precious resource, so we need explicit imageblocks to pack more data into that space.
But a static tile memory layout for an entire pass is still unlikely to fit, so we need to flexibly transition tile memory layouts as we move through the different phases of our computation.
Fragment-based tile pipelines enable this transitioning.
The barrier semantics I described earlier ensure that all tile memory access is complete before the transition begins.
And since fragment shaders copy data to and from imageblocks, we can ensure that each pixel is transitioned atomically.

Let's look at an example.
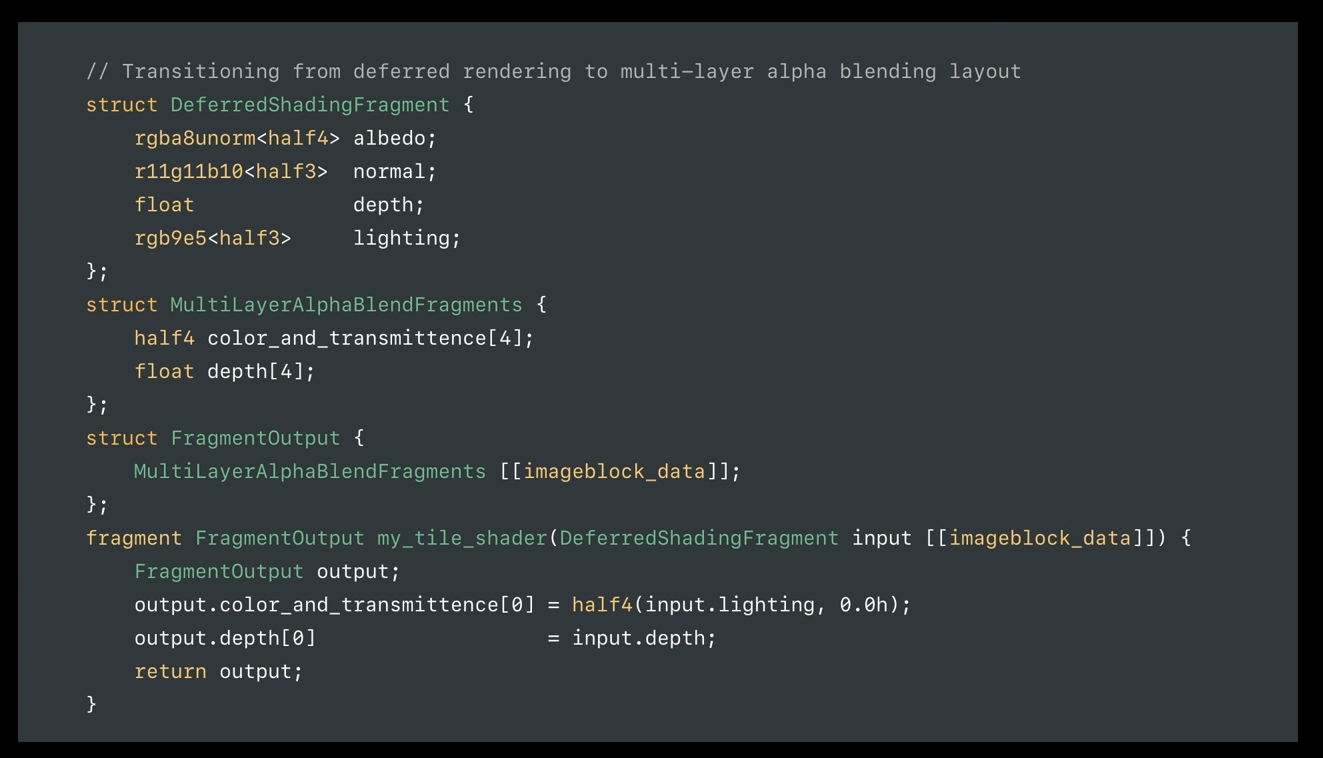
In this example, we finished with our deferred rendering phase and would like to reconfigure the imageblock to implement an approximate order-independent transparency technique called Multi-Layer Alpha Blending.
We do so using a fragment-based tile function that takes the old layout as input and returns the new layout.
And as is often the case, you often need to initialize the new layout using data from the old layout.
Here we bring over the final lit value from the deferred rendering phase.
To better understand tile shading, please be sure to check out our sample code.
It demonstrates how to efficiently forward shade with many lights in a single pass.
Tile shading is used to cull lights that do not affect the tile.

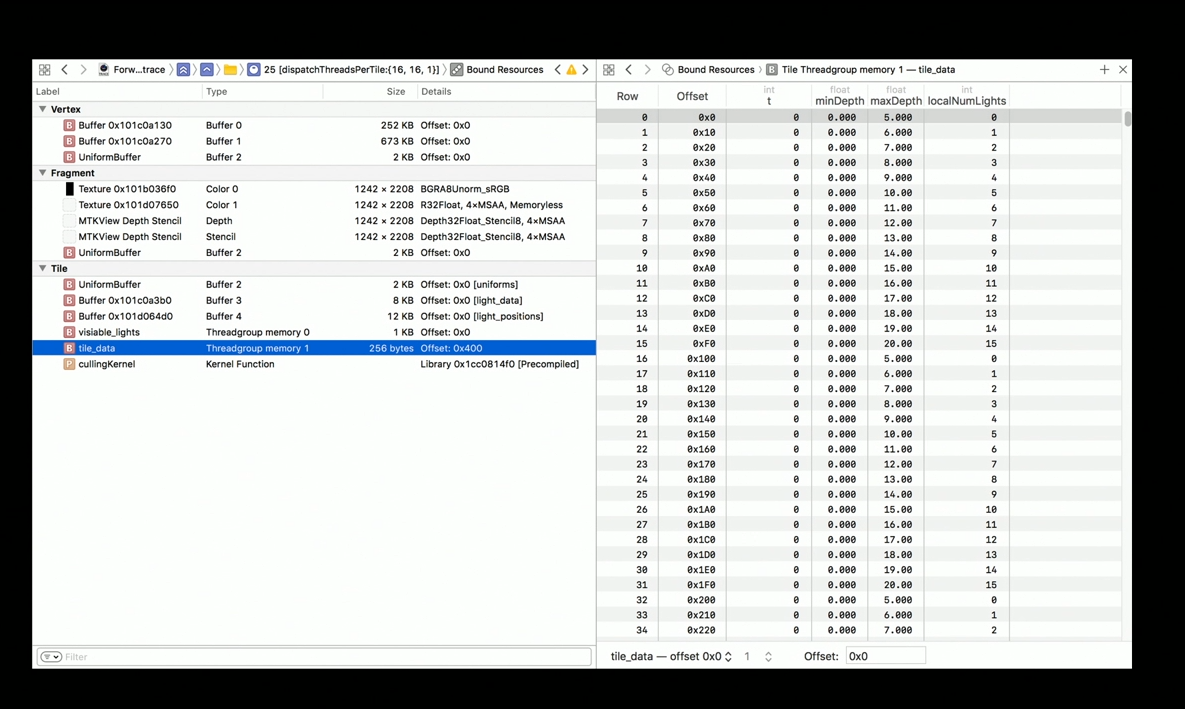
Finally, the GPU Debugger in Xcode makes inspecting threadgroup memory easy by formatting the data based on how you use it in your shader.

After taking a capture with Xcode's GPU Debugger, you can see each threadgroup memory as buffers in the tile section of the bound resources view.
From there, you can use the buffer viewer to inspect the data formatted in same way that your shader uses it.
In this presentation, we saw how tile shading enables developers to analyze and manipulate whole tile contents, communicate across draws, and repurpose tile memory through different phases of computation.
Taken together, tile shaders enable developers to merge multiple render and compute passes in order to better leverage the higher bandwidth and lower power tile memory of the A11 GPU.
For more information about Metal 2 and links to the sample code please visit the Developer website at developer.apple.com/metal.

虽然并非全部原创,但还是希望转载请注明出处:电子设备中的画家|王烁 于 2022 年 10 月 9 日发表,原文链接(http://geekfaner.com/shineengine/WWDCTechTalks_Metal2onA11-Imageblocks.html)